Neural Machine Translation communication system
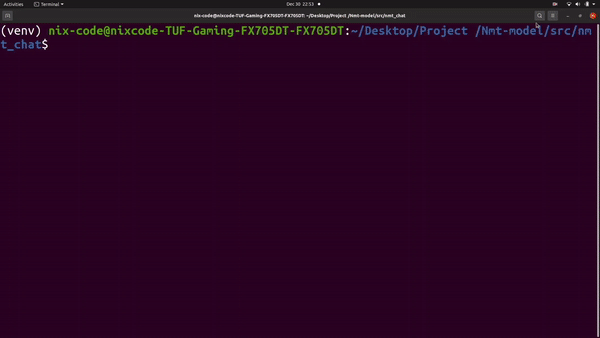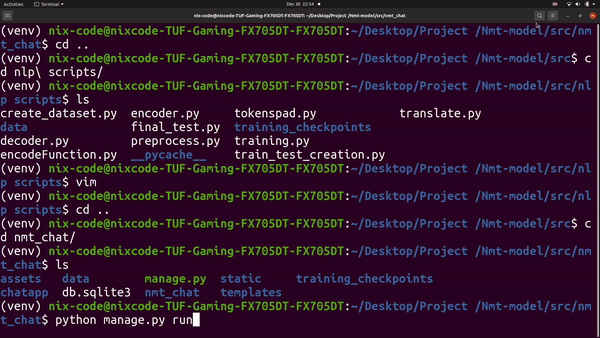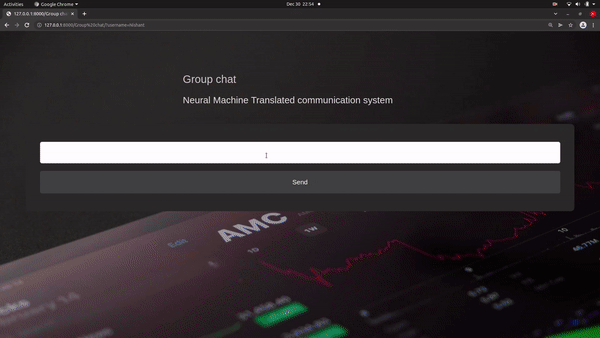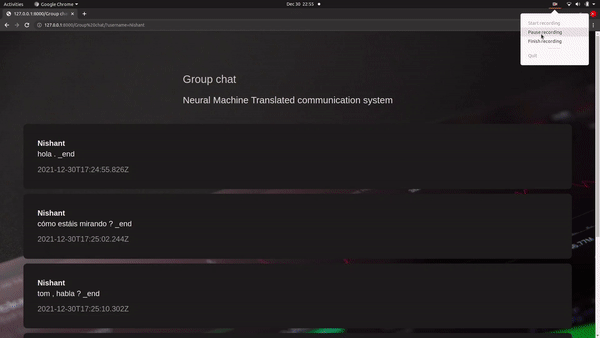
The model is basically direct to convert one source language to another targeted language using encoder and decoder architecture. The model encodes the message sent by the sender to a vector of fixed length and decoder generates the translated message which is received by the receiver in their communication system(chat application) automatically.
Table Of Contents
Prerequisites
- Install python packages such as
numpypandasTensorflowDjangomatplotlib
Contribute
- Fork the repository
- Commit your changes
- push to the branch & open a pull request
About
The model is trained using the spanish-english dataset with 100 epochs. The dataset contains about 110k rows and took about 4 hours to train using Nvidia GTX 1650 graphics card.
Clone the project
git clone [email protected]:Nix-code/Nix-code-Neural-Machine-Translation-communication-system-.git
Basic knowledge of Django is must, as the Neural Machine Translation model is deployed on Django

 12 Feb 16, 2022
12 Feb 16, 2022
 19 Dec 13, 2022
19 Dec 13, 2022
 2.5k Jan 07, 2023
2.5k Jan 07, 2023
 27 Aug 11, 2022
27 Aug 11, 2022
 2 Feb 03, 2022
2 Feb 03, 2022
 16 Sep 09, 2022
16 Sep 09, 2022
 3 May 19, 2022
3 May 19, 2022
 3 Jan 17, 2022
3 Jan 17, 2022
 1 Aug 19, 2021
1 Aug 19, 2021
 1.6k Dec 29, 2022
1.6k Dec 29, 2022
 72 Dec 09, 2022
72 Dec 09, 2022
 4.6k Jan 01, 2023
4.6k Jan 01, 2023
 1.1k Dec 25, 2022
1.1k Dec 25, 2022
 382 Jan 07, 2023
382 Jan 07, 2023
 3.1k Jan 07, 2023
3.1k Jan 07, 2023
 112 Dec 05, 2022
112 Dec 05, 2022
 203 Dec 20, 2022
203 Dec 20, 2022
 1 Jun 28, 2022
1 Jun 28, 2022
 1.5k Jan 02, 2023
1.5k Jan 02, 2023
 575 Dec 31, 2022
575 Dec 31, 2022