Render In-between: Motion Guided Video Synthesis for Action Interpolation
[Paper] [Supp] [arXiv] [4min Video]

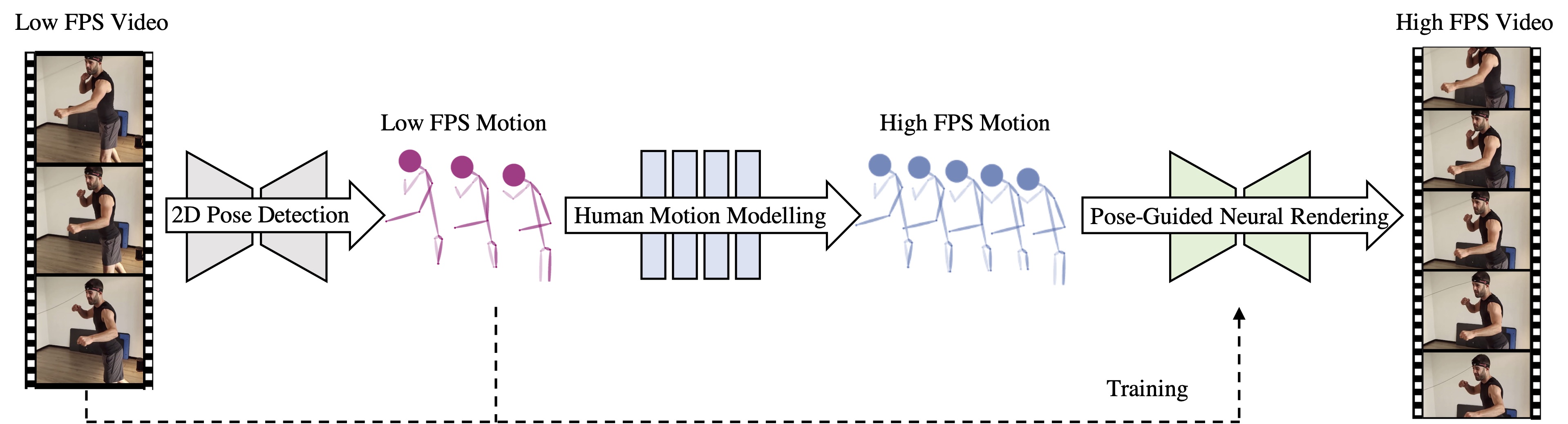
This is the official Pytorch implementation for our work. Our proposed framework is able to synthesize challenging human videos in an action interpolation setting. This repository contains three subdirectories, including code and scripts for preparing our collected HumanSlomo dataset, the implementation of human motion modeling network trained on the large-scale AMASS dataset, as well as the pose-guided neural rendering model to synthesize video frames from poses. Please check each subfolder for the detailed information and how to execute the code.
HumanSlomo Dataset

We collected a set of high FPS creative commons of human videos from Youtube. The videos are manually split into several continuous clips for training and test. You can also build your video dataset using the provided scripts.
Human Motion Modeling

Our human motion model is trained on a large scale motion capture dataset AMASS. We provide code to synthesize 2D human motion sequences for training from the SMPL parameters defined in AMASS. You can also simply use the pre-trained model to interpolate low-frame-rate noisy human body joints to high-frame-rate motion sequences.
Pose Guided Neural Rendering

The neural rendering model learned to map the pose sequences back to the original video domain. The final result is composed with the background warping from DAIN and the generated human body according to the predicted blending mask autoregressively. The model is trained in a conditional image generation setting, given only low-frame-rate videos as training data. Therefore, you can train your custom neural rendering model by constructing your own video dataset.
Quick Start
Download this example action clip which includes necessary input files for our pipeline.
The first step is generating high FPS motion from low FPS poses with our motion modeling network.
cd Human_Motion_Modelling
python inference.py --pose-dir ../example/input_poses --save-dir ../example/ --upsample-rate 2
Next we will map high FPS poses back to video frames with our pose-guided neural rendering. Download the checkpoint files to the corresponding folder to run the model.
cd Pose_Guided_Neural_Rendering
python inference.py --input-dir ../example/ --save-dir ../example/
Citation
@inproceedings{ho2021render,
author = {Hsuan-I Ho, Xu Chen, Jie Song, Otmar Hilliges},
title = {Render In-between: Motion GuidedVideo Synthesis for Action Interpolation},
booktitle = {BMVC},
year = {2021}
}
Acknowledgement
We use the pre-processing code in AMASS to synthesize our motion dataset. AlphaPose is used for generating 2D human body poses. DAIN is used for warping background images. Our human motion modeling network is based on the transformer backbone in DERT. Our pose-guided neural rendering model is based on imaginaire. We sincerely thank these authors for their awesome work.

 57 Dec 04, 2022
57 Dec 04, 2022
 47 Dec 09, 2022
47 Dec 09, 2022
 4 Oct 16, 2022
4 Oct 16, 2022
 288 Dec 31, 2022
288 Dec 31, 2022
 5.2k Jan 05, 2023
5.2k Jan 05, 2023
 17 Jun 03, 2022
17 Jun 03, 2022
 4 Jun 20, 2021
4 Jun 20, 2021
 23.6k Dec 31, 2022
23.6k Dec 31, 2022
 44 Dec 27, 2022
44 Dec 27, 2022
 3 May 08, 2022
3 May 08, 2022
 1.3k Dec 25, 2022
1.3k Dec 25, 2022
 73 Jul 21, 2022
73 Jul 21, 2022
 29 Nov 09, 2022
29 Nov 09, 2022
 22 Aug 23, 2022
22 Aug 23, 2022
 71 Dec 01, 2022
71 Dec 01, 2022
 36 Dec 29, 2022
36 Dec 29, 2022
 13 Nov 30, 2022
13 Nov 30, 2022
 584 Jan 02, 2023
584 Jan 02, 2023
 146 Dec 29, 2022
146 Dec 29, 2022
 9 Dec 11, 2022
9 Dec 11, 2022