highway-env
![]()



A collection of environments for autonomous driving and tactical decision-making tasks
An episode of one of the environments available in highway-env.
Try it on Google Colab! 
The environments
Highway
env = gym.make("highway-v0")
In this task, the ego-vehicle is driving on a multilane highway populated with other vehicles. The agent's objective is to reach a high speed while avoiding collisions with neighbouring vehicles. Driving on the right side of the road is also rewarded.

The highway-v0 environment.
A faster variant, highway-fast-v0 is also available, with a degraded simulation accuracy to improve speed for large-scale training.
Merge
env = gym.make("merge-v0")
In this task, the ego-vehicle starts on a main highway but soon approaches a road junction with incoming vehicles on the access ramp. The agent's objective is now to maintain a high speed while making room for the vehicles so that they can safely merge in the traffic.

The merge-v0 environment.
Roundabout
env = gym.make("roundabout-v0")
In this task, the ego-vehicle if approaching a roundabout with flowing traffic. It will follow its planned route automatically, but has to handle lane changes and longitudinal control to pass the roundabout as fast as possible while avoiding collisions.
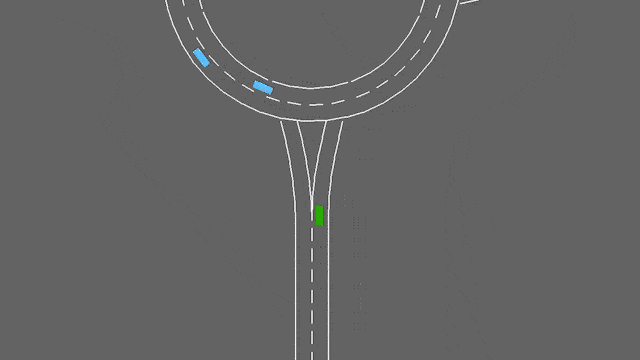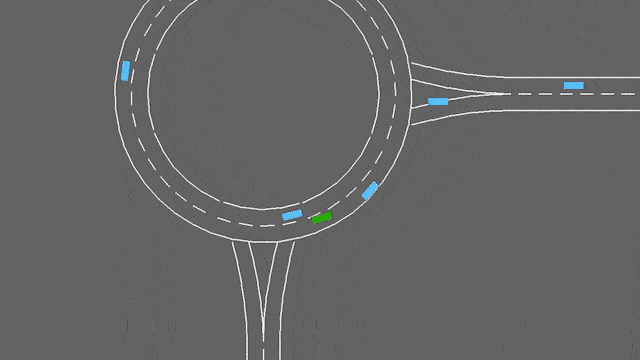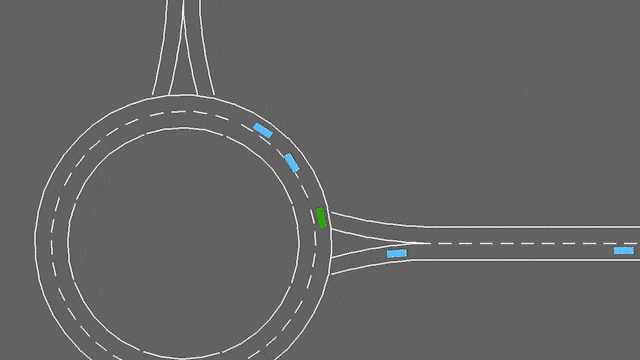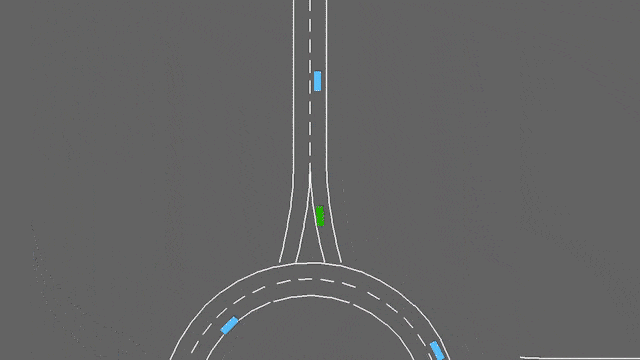
The roundabout-v0 environment.
Parking
env = gym.make("parking-v0")
A goal-conditioned continuous control task in which the ego-vehicle must park in a given space with the appropriate heading.
The parking-v0 environment.
Intersection
env = gym.make("intersection-v0")
An intersection negotiation task with dense traffic.
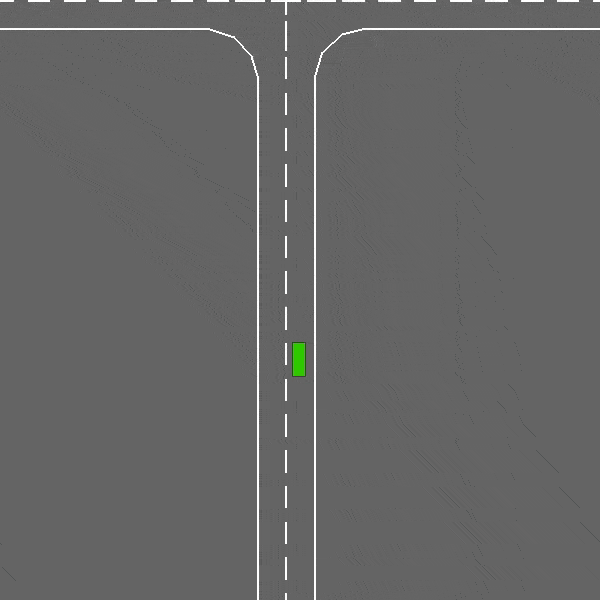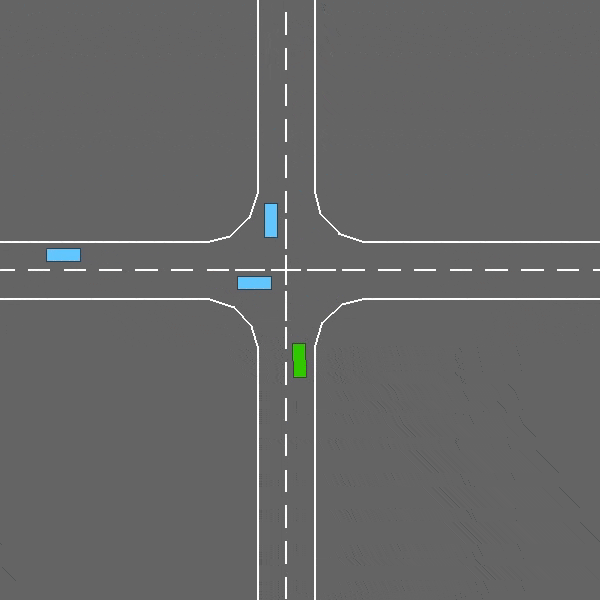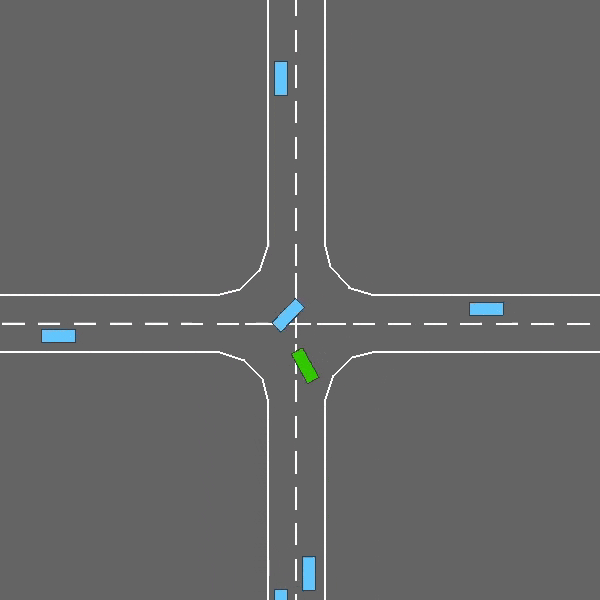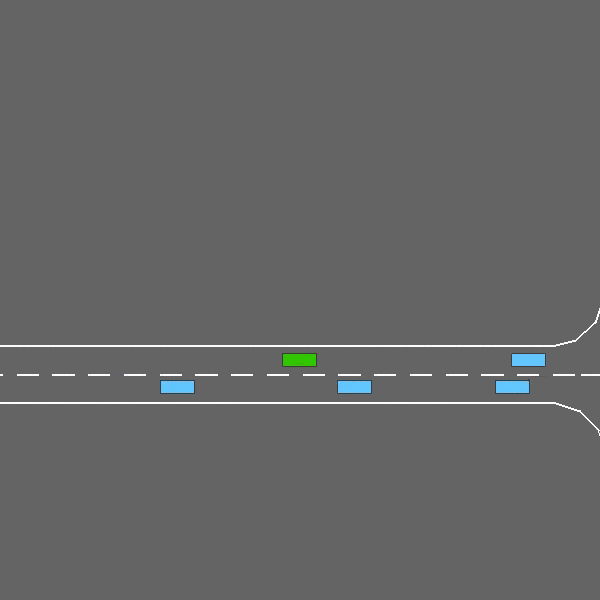
The intersection-v0 environment.
Racetrack
env = gym.make("racetrack-v0")
A continuous control task involving lane-keeping and obstacle avoidance.
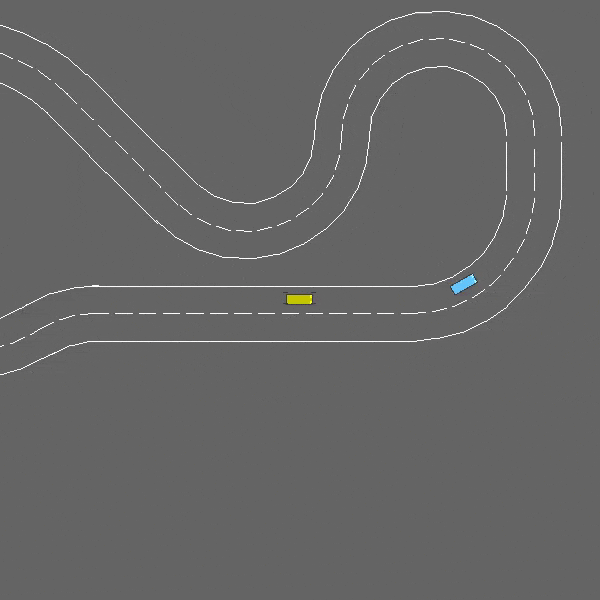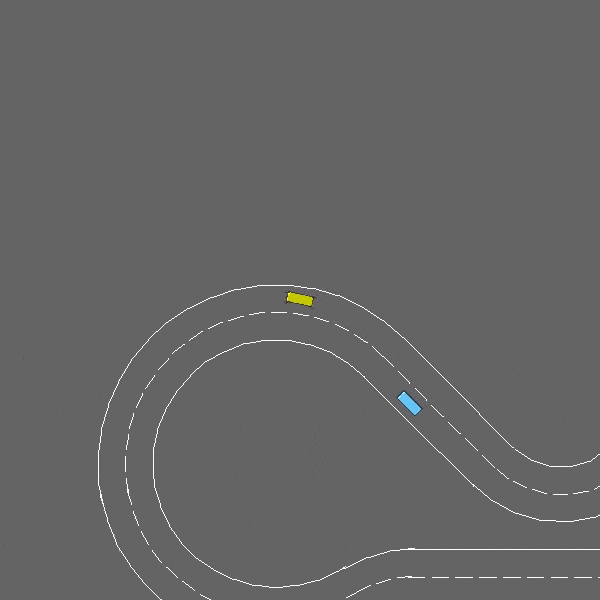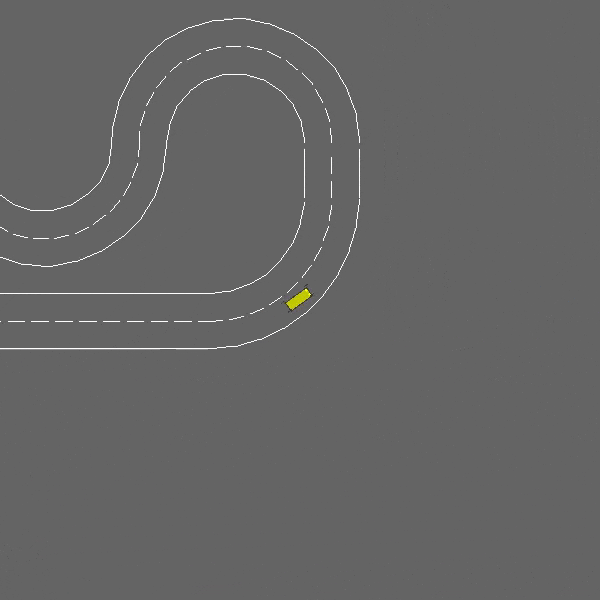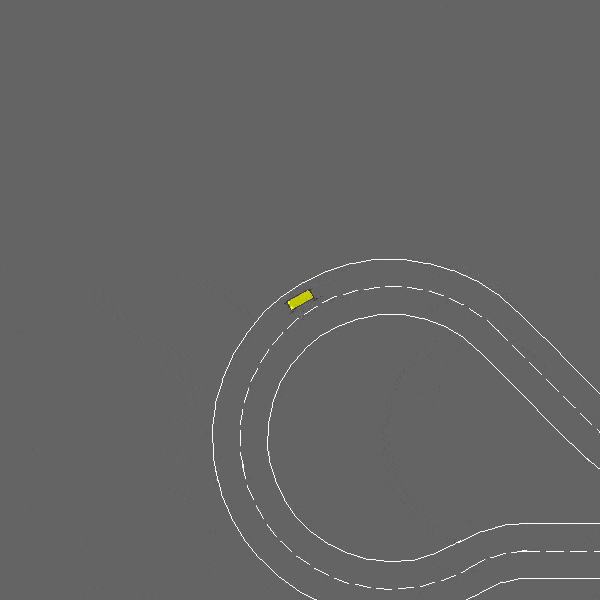
The racetrack-v0 environment.
Examples of agents
Agents solving the highway-env environments are available in the eleurent/rl-agents and DLR-RM/stable-baselines3 repositories.
See the documentation for some examples and notebooks.
Deep Q-Network
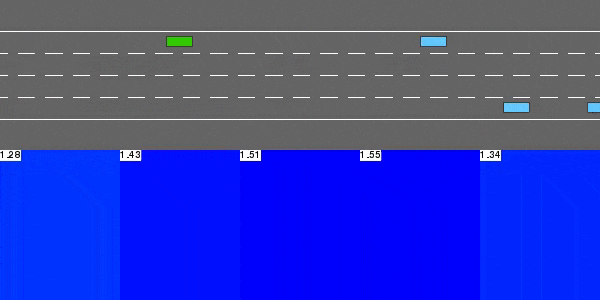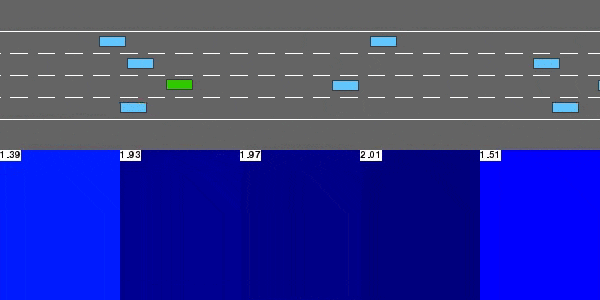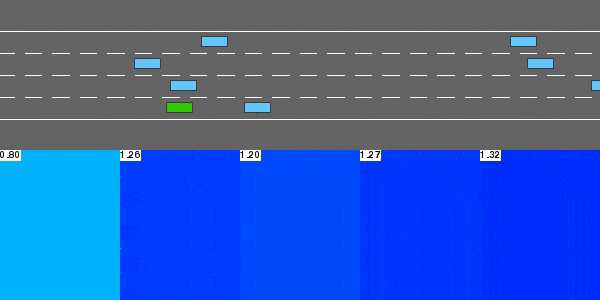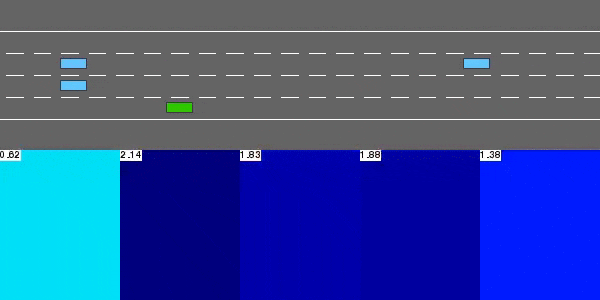
The DQN agent solving highway-v0.
This model-free value-based reinforcement learning agent performs Q-learning with function approximation, using a neural network to represent the state-action value function Q.
Deep Deterministic Policy Gradient

The DDPG agent solving parking-v0.
This model-free policy-based reinforcement learning agent is optimized directly by gradient ascent. It uses Hindsight Experience Replay to efficiently learn how to solve a goal-conditioned task.
Value Iteration
The Value Iteration agent solving highway-v0.
The Value Iteration is only compatible with finite discrete MDPs, so the environment is first approximated by a finite-mdp environment using env.to_finite_mdp(). This simplified state representation describes the nearby traffic in terms of predicted Time-To-Collision (TTC) on each lane of the road. The transition model is simplistic and assumes that each vehicle will keep driving at a constant speed without changing lanes. This model bias can be a source of mistakes.
The agent then performs a Value Iteration to compute the corresponding optimal state-value function.
Monte-Carlo Tree Search
This agent leverages a transition and reward models to perform a stochastic tree search (Coulom, 2006) of the optimal trajectory. No particular assumption is required on the state representation or transition model.

The MCTS agent solving highway-v0.
Installation
pip install highway-env
Usage
import gym
import highway_env
env = gym.make("highway-v0")
done = False
while not done:
action = ... # Your agent code here
obs, reward, done, info = env.step(action)
env.render()
Documentation
Read the documentation online.
Citing
If you use the project in your work, please consider citing it with:
@misc{highway-env,
author = {Leurent, Edouard},
title = {An Environment for Autonomous Driving Decision-Making},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/eleurent/highway-env}},
}
List of publications & preprints using highway-env (please open a pull request to add missing entries):
- Approximate Robust Control of Uncertain Dynamical Systems (Dec 2018)
- Interval Prediction for Continuous-Time Systems with Parametric Uncertainties (Apr 2019)
- Practical Open-Loop Optimistic Planning (Apr 2019)
- α^α-Rank: Practically Scaling α-Rank through Stochastic Optimisation (Sep 2019)
- Social Attention for Autonomous Decision-Making in Dense Traffic (Nov 2019)
- Budgeted Reinforcement Learning in Continuous State Space (Dec 2019)
- Multi-View Reinforcement Learning (Dec 2019)
- Reinforcement learning for Dialogue Systems optimization with user adaptation (Dec 2019)
- Distributional Soft Actor Critic for Risk Sensitive Learning (Apr 2020)
- Bi-Level Actor-Critic for Multi-Agent Coordination (Apr 2020)
- Task-Agnostic Online Reinforcement Learning with an Infinite Mixture of Gaussian Processes (Jun 2020)
- Beyond Prioritized Replay: Sampling States in Model-Based RL via Simulated Priorities (Jul 2020)
- Robust-Adaptive Interval Predictive Control for Linear Uncertain Systems (Jul 2020)
- SMART: Simultaneous Multi-Agent Recurrent Trajectory Prediction (Jul 2020)
- Delay-Aware Multi-Agent Reinforcement Learning for Cooperative and Competitive Environments (Aug 2020)
- B-GAP: Behavior-Guided Action Prediction for Autonomous Navigation (Nov 2020)
- Model-based Reinforcement Learning from Signal Temporal Logic Specifications (Nov 2020)
- Robust-Adaptive Control of Linear Systems: beyond Quadratic Costs (Dec 2020)
- Assessing and Accelerating Coverage in Deep Reinforcement Learning (Dec 2020)
- Distributionally Consistent Simulation of Naturalistic Driving Environment for Autonomous Vehicle Testing (Jan 2021)
- Interpretable Policy Specification and Synthesis through Natural Language and RL (Jan 2021)
- Deep Reinforcement Learning Techniques in Diversified Domains: A Survey (Feb 2021)
- Corner Case Generation and Analysis for Safety Assessment of Autonomous Vehicles (Feb 2021)
- Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment (Feb 2021)
- Building Safer Autonomous Agents by Leveraging Risky Driving Behavior Knowledge
- Quick Learner Automated Vehicle Adapting its Roadmanship to Varying Traffic Cultures with Meta Reinforcement Learning (Apr 2021)
- Deep Multi-agent Reinforcement Learning for Highway On-Ramp Merging in Mixed Traffic (May 2021)
- Accelerated Policy Evaluation: Learning Adversarial Environments with Adaptive Importance Sampling (Jun 2021)
- Learning Interaction-aware Guidance Policies for Motion Planning in Dense Traffic Scenarios (Jul 2021)
- Robust Predictable Control (Sep 2021)
PhD theses
- Reinforcement learning for Dialogue Systems optimization with user adaptation (2019)
- Safe and Efficient Reinforcement Learning for Behavioural Planning in Autonomous Driving (2020)
- Many-agent Reinforcement Learning (2021)
Master theses















![[Feature] Allow `config` to be set in `reset(options=...)`](https://avatars.githubusercontent.com/u/14953262?v=4)

 198 Jan 02, 2023
198 Jan 02, 2023
 121 Dec 24, 2022
121 Dec 24, 2022
 10 Oct 10, 2022
10 Oct 10, 2022
 27 Dec 02, 2022
27 Dec 02, 2022
 16 Dec 07, 2022
16 Dec 07, 2022
 30 Dec 12, 2022
30 Dec 12, 2022
 207 Dec 30, 2022
207 Dec 30, 2022
 23 Dec 07, 2022
23 Dec 07, 2022
 171 Dec 14, 2022
171 Dec 14, 2022
 9 Sep 01, 2022
9 Sep 01, 2022
 76 Dec 20, 2022
76 Dec 20, 2022
 305 Dec 21, 2022
305 Dec 21, 2022
 2 Dec 26, 2021
2 Dec 26, 2021
 880 Jan 07, 2023
880 Jan 07, 2023
 125 Dec 02, 2022
125 Dec 02, 2022
 23 Dec 16, 2022
23 Dec 16, 2022
 7 Oct 23, 2021
7 Oct 23, 2021
 0 Apr 20, 2022
0 Apr 20, 2022
 63 Sep 25, 2022
63 Sep 25, 2022
 1 Oct 24, 2021
1 Oct 24, 2021